原子操作是指保证指令以原子的方式执行,执行过程不会被打断。
独占内存访问指令
原子操作需要处理器提供硬件支持,不同的处理器体系结构在原子操作上会有不同的实现。 ARMv8使用两种方式来实现原子操作:一种是经典的独占加载(Load-Exclusive)和独占存储 (Store-Exclusive) 指令,这种实现方式叫作连接加载/条件存储(Load-Link/Store-Conditional, LL/SC);另一种是在ARMv8.1体系结构上实现的LSE指令。
LL/SC最早用于并发与同步访问内存的CPU指令。该方法分为两个部分。
- LL表示从指定内存地址读取一个值,并且处理器会监控这个内存地址,看其他处理器是否修改该内存地址。
- SC表示如果这段时间内其他处理器没有修改该内存地址,则把新值写入该地址。
因此整个流程就是LL读取指定地址的值,进行一些处理,然后通过SC进行写回。如果SC失败,那么重新开始整个操作。
ARMV8中的LDXR和STXR指令就实现了这种机制。
ldxr <xt>, [xn|sp]
stxr <ws>, <xt>, [xn|sp]- ldxr:把xn或者sp地址的值原子地加载到xt寄存器中
- stxr:把xt寄存器的值原子地存储到xn或者sp地址里,执行的结果反映到ws寄存器,为0表示执行成功,非0表示执行失败
ldxr和stxr指令还可以和加载-获取以及存储-释放内存屏障原语结合使用,构成一个类似于临界区的内存屏障,例如自旋锁的实现:
func spin_lock
mov w2, #1
sevl
l1: wfe
l2: ldaxr w1, [x0]
cbnz w1, l1
stxr w1, w2, [x0]
cbnz w1, w2
ret
endfunc spin_lock独占监视器会把对应内存地址标记为独占访问模式,保证以独占的方式来访问这个内存地址,不受其他因素的影响。而stxr是有条件的存储指令,它会把新数据写入ldxr指令标记独占访问的内存地址里
LDXR指令本质上也是LDR指令,只不过在ARM64处理器内部使用一个独占监视器来监 视它的状态。独占监视器一共有两个状态一放访问状态和独占访问状态。
当CPU通过LDXR指令从内存加载数据时,CPU会把这个内存地址标记为独占访问,然 后CPU内部的独占监视器的状态变成独占访问状态。当CPU执行STXR指令的时候,需要根 据独占监视器的状态来做决定。
如果独占监视器的状态为独占访问状态,并且STXR指令要存储的地址正好是刚才使用 LDXR指令标记过的,那么STXR指令存储成功,STXR指令返回0,独占监视器的状态变成 开放访问状态。
如果独占监视器的状态为开放访问状态,那么STXR指令存储失败,STXR指令返回1, 独占监视器的状态不变,依然保持开放访问状态。
原子内存访问操作指令
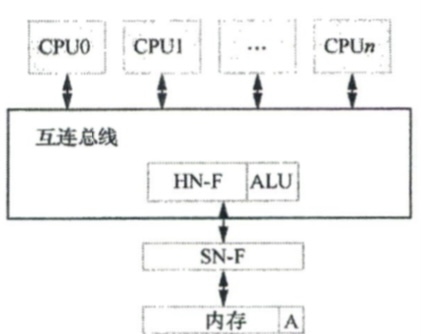
在ARMV8.1体系结构中新增了原子内存访问操作指令(atomic memory access instruction),这个也称为LSE(large system extension)。原子内存访问操作指令需要AMBA5总线中的CHI(coherent hub interface)的支持。AMBA5总线引入了原子事务,允许将原子操作发送到数据,并允许原子操作在靠近数据的地方执行,例如在互连总线上执行原子算术和逻辑操作,而不需要加载到高速缓存中处理。原子事务非常适合要操作的数据离处理器核心比较远的情况,例如数据在内存中。
举个例子,假设地址a存储了一个计数值,CPU0执行一条stadd原子内存访问指令把a计数加一:
- CPU0执行stadd指令时,会发出一个原子存储事务请求到互联总线上
- 互联总线上的HN-F接收到请求。HN-F会协同SN-F以及ALU来完成加法原子操作。
- 因为原子存储事务时不需要等待回应的事务,CPU不会跟踪该事务的处理过程,所以CPU0发送完该事务就认为stadd指令已经执行完
 095383E2-D94D-4AC8-B30C-3CD26803FCC9.jpeg
095383E2-D94D-4AC8-B30C-3CD26803FCC9.jpeg综上所述,原子内存访问操作指令与独占内存访问指令最大的区别在于效率。
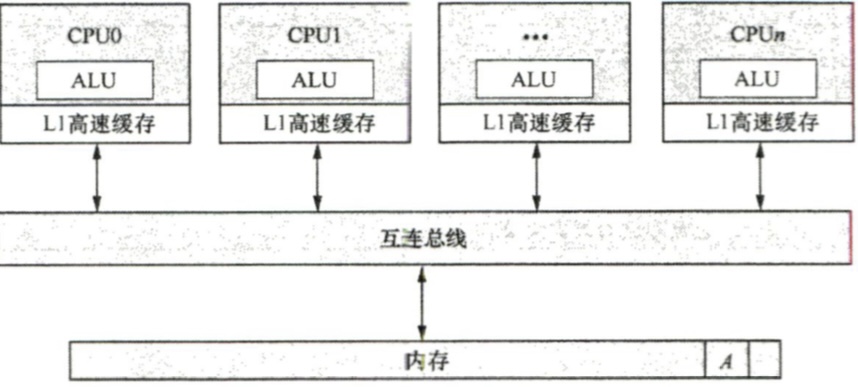
假如自旋锁lock变量存储在内存中。与之相比,在独占内存访问架构下,ALU位于每个CPU内核内部。例如,使用LDXR和 STXR指令来对某地址上的A计数进行原子加1操作,首先使用LDXR指令加载计数A到L1 高速缓存中,由于其他CPU可能缓存了/数据,因此需要通过MESI协议来处理L1高速缓存 一致性的问题,然后利用CPU内部的ALU来完成加法运算,最后通过STXR指令写回内存中。 因此,整个过程中,需要多次处理高速缓存一致性的情况,效率低下。独占内存访问架构如图所示。假设CPU0〜CPUn同时对计数A进行独占访问,即通过LDXR和STXR指令来 实现“读-修改-写”操作,那么计数工会被加载到CPU0〜CPU”的L1高速缓存中,CPU0〜CPU" 将会引发激烈的竞争,导致高速缓存颠簸,系统性能下降。而原子内存操作指令则会在互连总 线中的HN-F节点中对所有发起访问的CPU请求进行全局仲裁,并且在HN-F节点内部完成算 术运算,从而避免高速缓存颠簸消耗的总线带宽。
 IMG_0496.jpeg
IMG_0496.jpeg使用独占内存访问指令会导致所有内CPU核都把锁加载到L1高速缓存中,然后不停地尝 试获取锁(使用LDXR指令来读取锁)和检查独占监视器的状态,导致高速缓存颠簸。这个场 景在NUMA体系结构下会变得更糟糕,远端节点(remote node)的CPU需要不断地跨节点访 问数据。另外一个问题是不公平,当锁持有者释放锁时,所有的CPU都需要抢这把锁(使用 STXR指令写这个lock变量),有可能最先申请锁的CPU反而没有抢到锁。
如果使用原子内存访问操作指令,那么最先申请这个锁的CPU内核会通过CHI互连总线的 HN-F节点完成算术和逻辑运算,不需要把数据加载到L1高速缓存,而且整个过程都是原子的。
LSE指令中主要新增了三类指令:
- 比较并交换(compare and swap CAS)指令
- 原子内存访问指令,用于原子地加载内存地址的值,然后进行加法运算。stadd指令原子地对内存地址的值进行加法运算,然后把结果存储到这个内存地址里。进一步可以细分为原子加载指令(先原子地加载,然后做运算)和原子存储指令(先运算,然后原子地存储)
- 交换指令
原子加载指令的格式如下
ld<op> <xs>, <xt>, [<xn|sp>]op表示操作后缀,包括add、clr、set、eor等。指令中的[<xn|sp>]表示以xn或者sp寄存器中的值作为地址。所以,原子加载指令对[xn]的值与xs寄存器的值执行对应操作,并更新结果到以xn寄存器的值为地址的内存中,最后xt寄存器返回[xn]的旧值。
原子存储操作的指令格式如下
st<op> <xs>, [<xn|sp>]对xn地址的值和xs寄存器的值做一个操作,然后把结果存储到xn寄存器中。
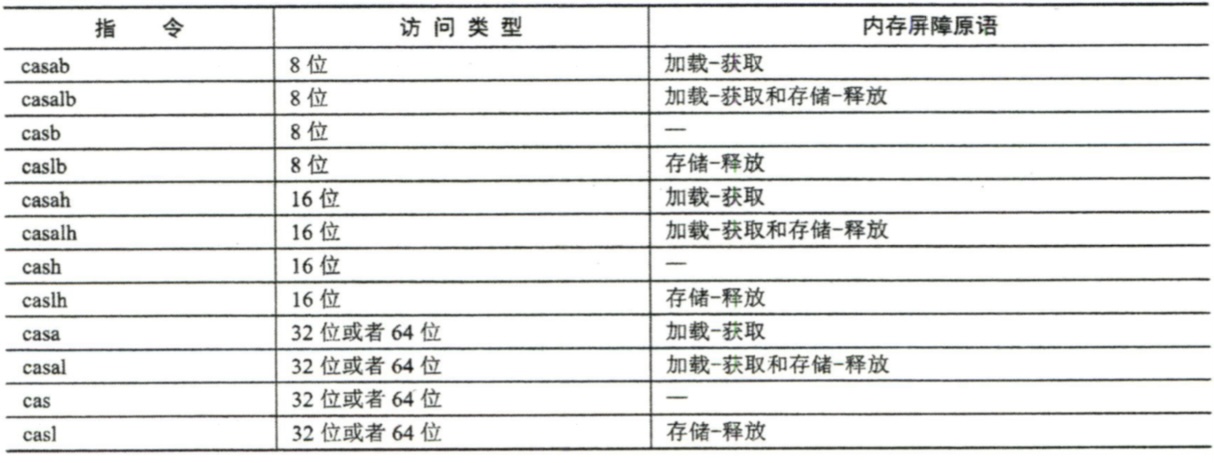
CAS指令在无锁实现中起到非常重要的作用。它的基本思路是检查ptr指向的值与expected是否相等。若相等,则把new的值赋值给ptr,否则什么都不做。不管是否相等,最终都会返回ptr的旧值,用于判断指令是否值性成功。
 IMG_0497.jpeg
IMG_0497.jpegWFE指令在自旋锁中的应用
// void spin_lock(spinlock_t *lock)
func spin_lock
mov w2, #1
1:mov w1, wzr
2:casa w1, w2, [x0]
cbz w1, 3f
ldxr w1, [x0]
cbz w1, 2b
wfe
b 1b
3:
ret
endfunc